Hi Friends it’s our first step is to get knowledge on the Machine learning.
Is it Possible to make a machine knowledgeable ? Is not so funny ?
How the concept is differ from our traditional software development practice i.e. Web development, Application development or IoT based apps .
Let's try to explore and figure out the answer.AI is made-up of both hardware technologies and software methods which rely on intelligence to sense, think, reason & find patterns, predict, communicate and act faster than humans ever dreamed possible.
What is Machine Learning ?
Machine learning helps humans make data-driven decisions.Machine learning offers practical solutions that can maximize resource utilization, prolong the lifespan of IoT sensors, platforms and networks, and enables dynamic services architecture.
"Machine learning is a set of algorithms that train on a data set to make predictions or take actions in order to optimize some systems." -Vincent Granville
The word learning in machine learning means that the algorithms depend on some data, used as a training set, to fine-tune some model or algorithm parameters. This encompasses many techniques such as regression, naive Bayes or supervised clustering.The three most important points to remember about machine learning:
- First think is to know that there are three types of data-driven development: retrospective, here-and-now, and predictions.
- Machine learning is the technology that automatically finds patterns in your data and uses them to make predictions for new data points as they become available.
- Algorithms in decision making can be divided into rule-based decision making, statistical reasoning, machine learning and artificial intelligence.
I’m sharing a interesting video with you Real Time Object Reorganization
When Machine learning ?
Program has developed to predict, for example, traffic patterns at a busy intersection (task T), you can run it through a machine learning algorithm with data bout past traffic patterns (experience E) and, if it has successfully “learned”, it will then do better at predicting future traffic patterns (performance measure P).When you shop online, machine learning helps recommend other products you might like based on what you've purchased. When your credit card is swiped, machine learning compares the transaction to a database of transactions and helps detect fraud. When your robot vacuum cleaner vacuums a room, machine learning helps it decide whether the job is done.
Why is Machine Learning Require ?
What are the steps of Applied Machine Learning Process?
6-step process for classification and regression type problems, the common problem types at the heart of most machine learning problems. The process is as follows:
- Problem Definition: Understand and clearly describe the problem that is being solved.
- Analyze Data: Understand the information available that will be used to develop a model.
- Prepare Data: Discover and expose the structure in the dataset.
- Evaluate Algorithms: Develop a robust test harness and baseline accuracy from which to improve and spot check algorithms.
- Improve Results: Leverage results to develop more accurate models.
- Present Results: Describe the problem and solution so that it can be understood by third parties.
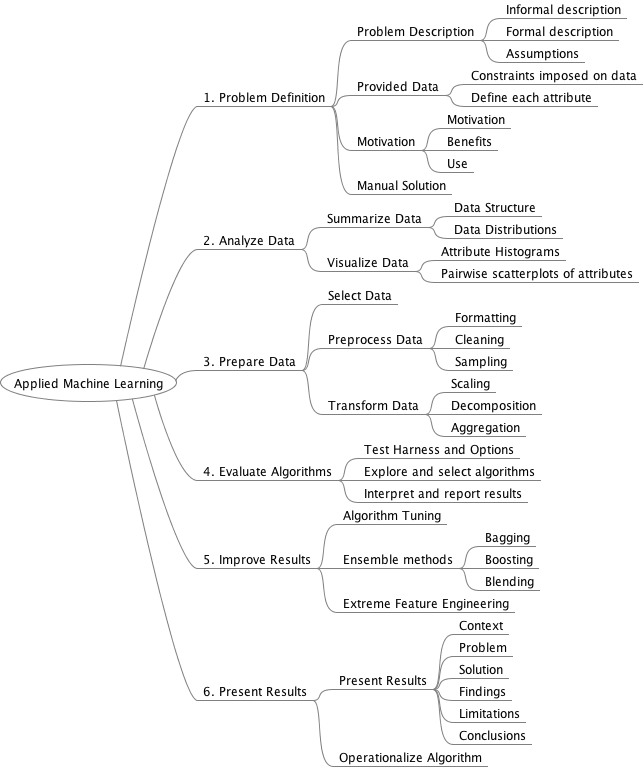
Basic steps of applying machine learning methods
Deploying a machine learning model typically takes the following five steps:
- Data collection.
- Data preprocessing: 1) Data cleaning; 2) Data transformation; 3) Divide data into training and testing sets.
- Build a model on training data.
- Evaluate the model on the test data.
- If the performance is satisfying, deploy to the real system.
1. Data Collection: At this stage, we want to collect all relevant data. For an online business, user click, search queries, and browsing information should be all be captured and saved into the database. In manufacturing, log data capture machine status and activities. Such data are used to produce maintenance schedules and predict required parts for replacement.
2. Data Preprocessing: The data used in Machine Learning describes factors, attributes, or features of an observation. Simple first steps in looking at the data include finding missing values. What is the significance of that missing value? Would replacing a missing data value with the median value for the feature be acceptable? For example, perhaps the person filling out a questionnaire doesn’t want to reveal his salary. This could be because the person has a very low salary or a very high salary. In this case, perhaps using other features to predict the missing salary data might be appropriate. One might infer the salary from the person’s zip code. The fact that the value is missing may be important. There are machine learning methods that ignore missing values and one of these could be used for this data set. 2) Data Transformation: In general we work with both numerical and categorical data. Numerical data consists of actual numbers, while categorical data have a few discrete values. Examples of categorical data include eye color, species type, marriage status, or gender. Actually a zip code is categorical. The zip code is a number but there is no meaning to adding two zip codes. There may or may not be an order to categorical data. For instance good, better, best is descriptive categorical data which has an order.
3) After the data has been cleaned and transformed it needs to be split into a training set and a test set.
3. Model Building: This training data set is used to create the model which is used to predict the answers for new cases in which the answer or target is unknown. For example, Section 1.3 describes how a decision tree is built using the training data set. Several different modeling techniques have been introduced and will be discussed in detail in future sections. Various models can be built using the same training data set. 4. Model Evaluation Once the model is built with the training data, it is used to predict the targets for the test data. First the target values are removed from the test data set. The model is applied to the test data set to predict the target values for the test data. The predicted value of the target is then compared with the actual target value. The accuracy of the model is the percentage of correct predictions made. These accuracies of can be used to compare the different models. Several other ways to compare model accuracy are discussed in the next section on Performance Evaluation.
5. Model Deployment: This is the most important step. If the speed and accuracy of the model is acceptable, then that model should be deployed in the real system. The model that is used in production should be made with all the available data. Models improve with the amount of available data used to create the model. The results of the model need to be incorporated in the business strategy. Data mining models provide valuable information which give companies great advantages. Obama won the election in part by incorporating the data mining results into his campaign strategy. The last chapter of this book provides information in how a company can incorporate data mining results into its daily business.