Explore Column Stored Index
What is a column store index?
A columnstore index is a type of data structure that’s used to store, manage and retrieve data that is stored in a columnar-style database.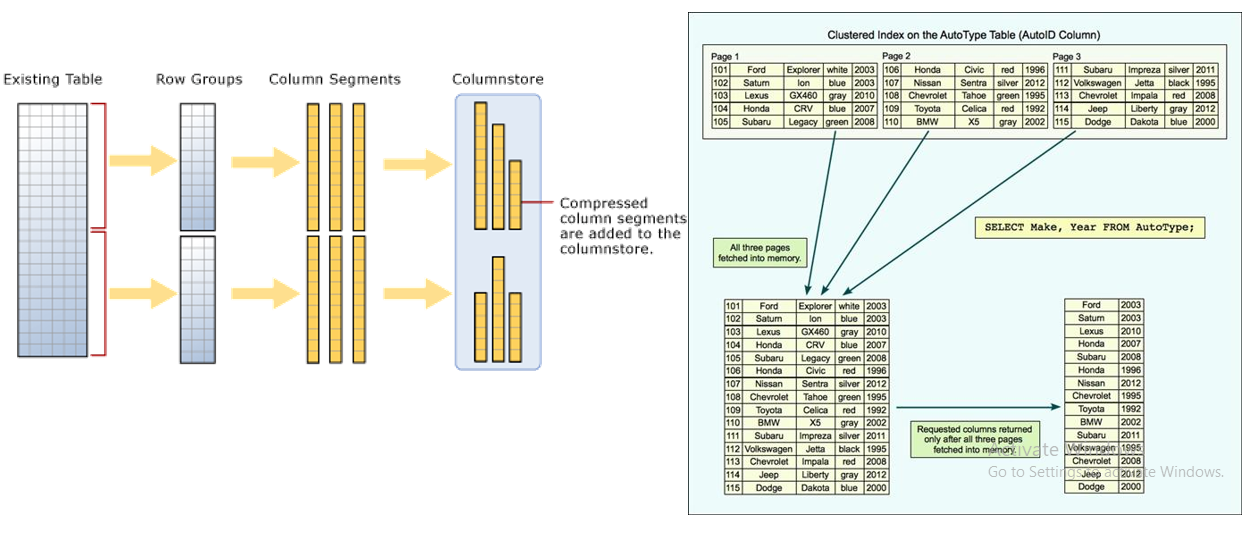
Why Column Store Index is used ?
- Best for queries that scan/aggregate large sets of data.
- IO Statistics - dramatically reduces # of logical reads.
- Smart IO and caching using aggressive read-ahead read strategy.
- In a regular index, indexed data from each row kept together on single page – and the data in each column spread across all pages of index
- Best for data warehouse/mart queries that scan/aggregate large amounts of data–might lower need for OLAP aggregation
- In a regular index, indexed data from each row kept together on single page – and the data in each column spread across all pages of index
- More and more functionality in DB engine (xVelocity, CDC)
- Some queries might run at least 10x faster (or more)
- Reduced storage costs and enhance performance.
- In Data Warehouses/Data Marts (in a star schema) ,queries performance is gained
- Load from Data Warehouses/Marts into OLAP Cubes
- SSAS OLAP Databases that use the ROLAP methodology or pass-through mode “might” benefit (more so in SQL 2014)
- New Analysis Services Tabular Model uses xVelocity engine
How to Create a column store index?
Expand the table. Under Indexes, right click and select New Index and then Clustered Column store Index as shown below :
Using SQL Server Management Studio :
[gallery ids=”1195,1196” type=”rectangular”]
Using T-SQL
CREATE CLUSTERED COLUMNSTORE INDEX [IXProductID] ON [dbo].[Product] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0, DATA_COMPRESSION = COLUMNSTORE) ON [PRIMARY] GO
Difference Between Column store vs. Row store index
Row store :
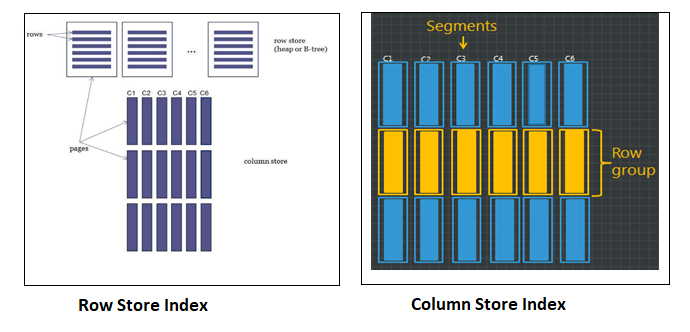
- Row store data is logically organized by rows and columns, and is physically stored in row-oriented data pages.
- Row store indexes perform best on queries that seek data by searching for a particular value or retrieving a small range of values.
Column store :
- The column store index is also logically organized as a table with rows and columns, but the data is physically stored in a column-wise data format.
- Column store indexes work well for mostly read-only queries with large data sets, like data warehousing workloads.
| Row Store Index | Column Store Index |
| Row store indexes tend to be better for online transaction processing (OLTP) workloads, which use more update and seek operations. | Column store indexes tend to be better for online analytical processing (OLAP) workloads, which use more read operations. |
| Row store indexes tend to be better at performing random reads and writes. | Column store indexes tend to be better for performing sequential reads and writes. |
| Row store data is logically organized by rows and columns, and is physically stored in row-oriented data pages. | The column store index is also logically organized as a table with rows and columns, but the data is physically stored in a column-wise data format. |
Limitations of Column Store Index
- Cannot be clustered, cannot be created against a view
- Cannot act as a PK or FK, cannot include sparse columns
- Can’t work on tables with Change Data Capture/Change Tracking or FileStream, can’t participate in replication, nor when page/row compression exists
- Cannot be used with certain data types, such as binary, text/image, rowversion/timestamp, CLR data types (hierarchyID/spatial), nor with data types created with MAX keyword…e.g. varchar(max)
- Cannot be used with Unique Identifier
- Cannot be used with decimal > 18
- Cannot be modified with ALTER – must be dropped and recreated
- Not optimized for certain statements (OUTER JOIN, UNION, NOT IN <subquery>)
- Not optimized for certain scenarios (high selectivity, queries lacking any aggregations)
- Issue OUTER JOIN: can’t use directly against table
- Will “work”, but will use slower row execution mode
- Must pre-aggregate separately and then do OUTER JOIN