Index in SQL Server
What is Index ?
SQL Indexes are used in relational databases to quickly retrieve data without reading the whole table. Similar to indexes of the books whose purpose is to find a topic quickly. Alternatively Indexes are special data structures associated with tables or views that help speed up the query.
- Faster query execution
- Enforce uniqueness & eliminate duplicates
- Already sorted list of table’s columns
- Full-Text Indexing gives capability to search against large object (LOB) data types char,
varchar, nchar, nvarchar, text, ntext, image, xml, or varbinary(max) and FILESTREAM
-- Example Create Index IDX_ProductId on table Products (ProductID)
What is Heap /Heap Table ?
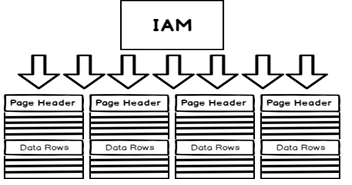
Data has stored without any underlying order If a table has no indexes or only has non-clustered indexes it is called a heap. Logically, the heap is comprised of an Index Allocation Map (IAM) that points to all pages within the heap. Each page will contain as many rows of data as will fit.
What is Cluster Table ?
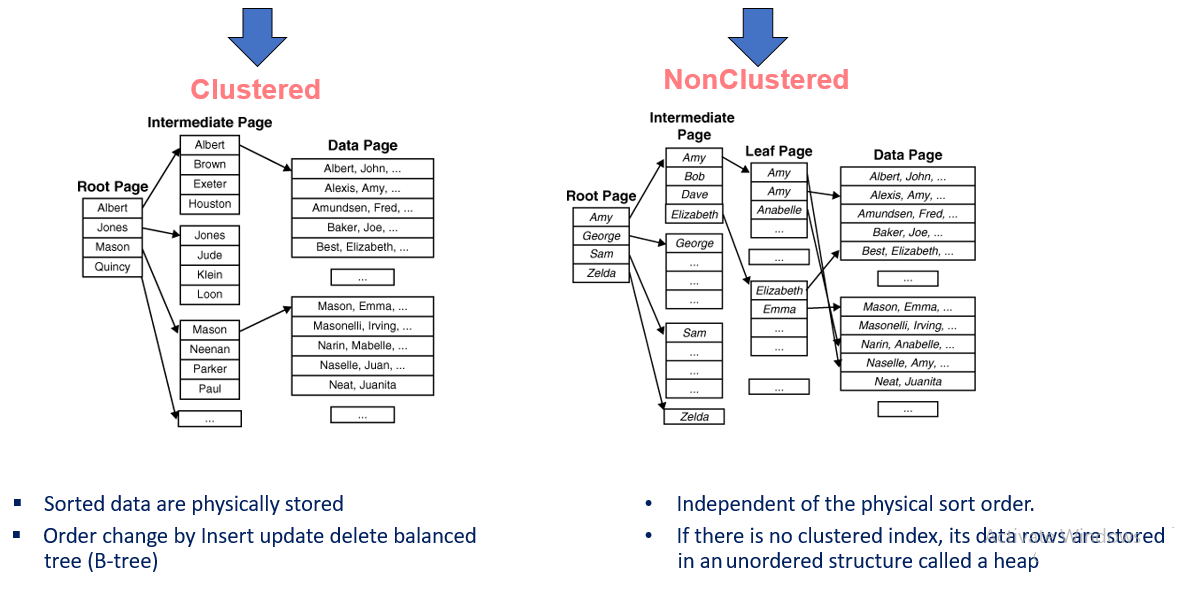
The name suggests itself, these tables have a Clustered Index. Data is stored in a specific order based on a Clustered Index key . By default no cluster index is created. This index provides an innate ordering for the table In a clustered index, when rows are inserted, updated, or deleted, the underlying order of data is retained. The pages in each level of the index are linked in a doubly-linked list.
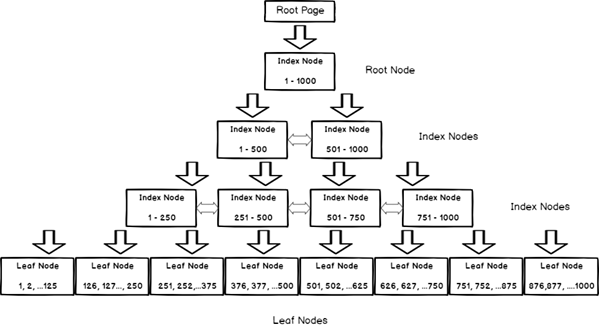
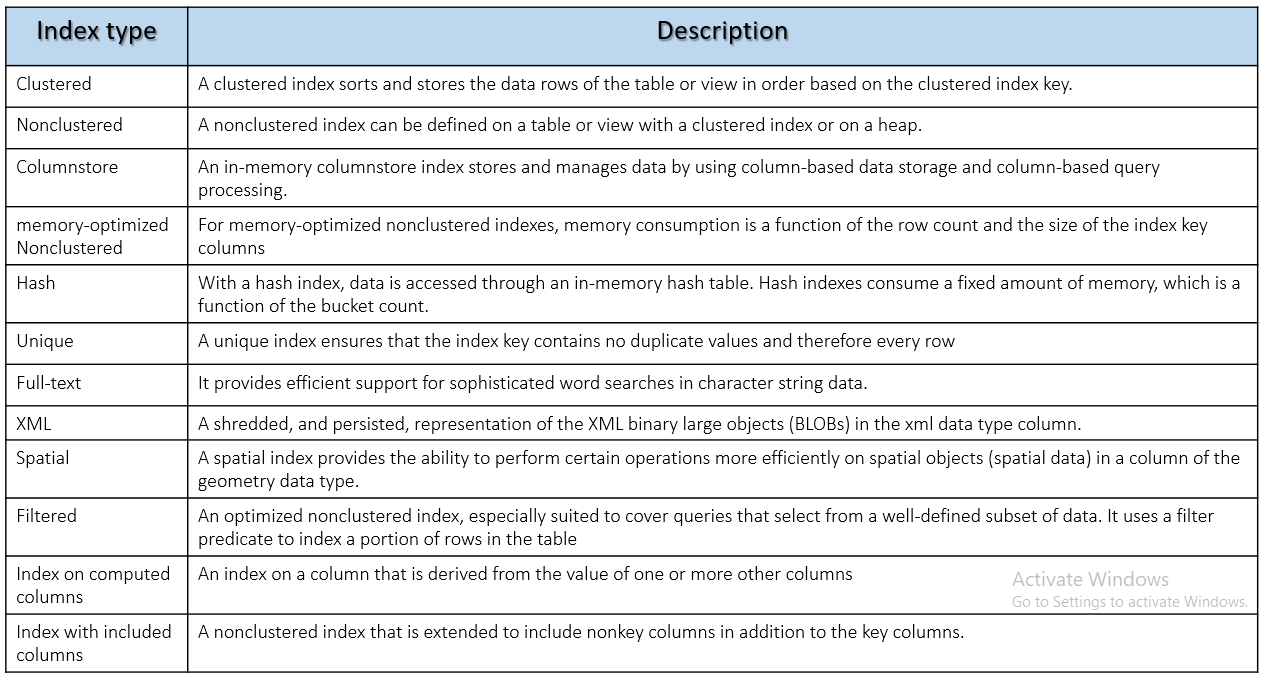
Type of Index
Clustered Tables vs Non-clustered Tables
Index Drawbacks
Indexes and Disk Space
Indexes are stored on the disk, and the amount of space required will depend on the size of the table, and the number and types of columns used in the index. Disk space is generally cheap enough to trade for application performance, particularly when a database serves a large number of users. To see the space required for a table, use the sp_spaceused system stored procedure in a query window.
EXEC sp_spaceused Orders
Given a table name (Orders), the procedure will return the amount of space used by the data and all indexes associated with the table, like so:
Name rows reserved data index_size unused ------- -------- ----------- ------ ---------- ------- Orders 830 504 KB 160 KB 320 KB 24 KB
According to the output above, the table data uses 160 kilobytes, while the table indexes use twice as much, or 320 kilobytes. The ratio of index size to table size can vary greatly, depending on the columns, data types, and number of indexes on a table.
Best practice to follow
Rebuild Indexes
The SQL Server Database Engine automatically maintains indexes whenever insert, update, or delete operations are made to the underlying data. Over time these modifications can cause the information in the index to become scattered in the database (fragmented). Fragmentation exists when indexes have pages in which the logical ordering, based on the key value, does not match the physical ordering inside the data file. Heavily fragmented indexes can degrade query performance and cause your application to respond slowly.
Index Fragmentation
Let’s insert a new row into the index and see what happens. SQL Server inserts a new row on the data page in case there is enough free space on that page, otherwise the following happens:
1.SQL Server allocates a new data page or even a new extent.
2.A part of data from the existing (old) data page transfers to a newly allocated data page.
3.In order to keep the logical sorting order in the index, pointers on both pages are updated.
As a consequence, we have 2 types of index fragmentation:
Logical fragmentation (also called external fragmentation or extent fragmentation) — the logical order of the pages does not correspond their physical order. As a result, SQL Server increases the number of physical (random) reads from the hard drive, making the read-ahead mechanism less efficient. This directly impacts to the query execution time, because random reading from the hard drive is far less efficient comparing to sequential reading.
Internal fragmentation — the data pages in the index contain free space. This lead to an increase in the number of logical reads during the query execution, because the index utilizes more data pages to store data.
What is Full Text Index?
Creating a full-text index does require some extra setup. As we mentioned in the opening full-text indexes require a full-text catalog for their storage. It’s important to note that this catalog name must be unique across all databases on the server. An example of the TSQL that can be used to create a catalog is below.
How to create a Full Text Index?
An example of the TSQL that can be used to create a catalog is below.
CREATE FULLTEXT CATALOG fulltextCatalog AS DEFAULT;
Once the catalog is created we can create the full-text index. There are two extra options to take note of below. The first option is the “KEY INDEX”. One requirement for creating full-text indexes is that the table has a unique key defined on it. This option associates the unique key with the full-text index. In order to get the best performance this unique key column should be an integer, usually it’s the primary key. The second option, “STOPLIST”, associates a stop list with the index. Any tokens that are part of the stop list are not populated in the index. Here is the TSQL to create the index.
DROP FULLTEXT INDEX ON Production.Document; CREATE FULLTEXT INDEX ON Production.Document(DocumentSummary) KEY INDEX PK_Document_DocumentNode WITH STOPLIST = SYSTEM;
Confirm Index Usage
This simple query listed below will check the document table for any summaries that contain the word “important” which should use the full-text index we just created.
SELECT * FROM Production.Document WHERE CONTAINS(DocumentSummary, 'important');
(The Finalization of article is on the way :) ….