Explore Table Partition in SQL Server
What Is SQL partitioning?
Using this technique a large table can be split into more manageable pieces without create multiple tables. Partition function is used for splitting into multiple pieces. Each individual partition can be physically stored ,accessible and maintainable separable .Partitioning allows tables, indexes, or index-organized tables to be subdivided into smaller, manageable pieces (partitions). Each partition has its name and possibly its storage characteristics.
How many partition support a single table ?
SQL Server 2019 (15.x) supports up to 15,000 partitions by default. In versions earlier than SQL Server 2012 (11.x), the number of partitions was limited to 1,000 by default. On x86-based systems, creating a table or index with more than 1,000 partitions is possible, but is not supported.
What is Partition Key ?
A single column or computed column can be used to partition a table that column is called partition column or partition key. All data types that are valid for use as index columns can be used as a partitioning column, except timestamp. The ntext, text, image, xml, varchar(max), nvarchar(max), or varbinary(max) data types cannot be specified.
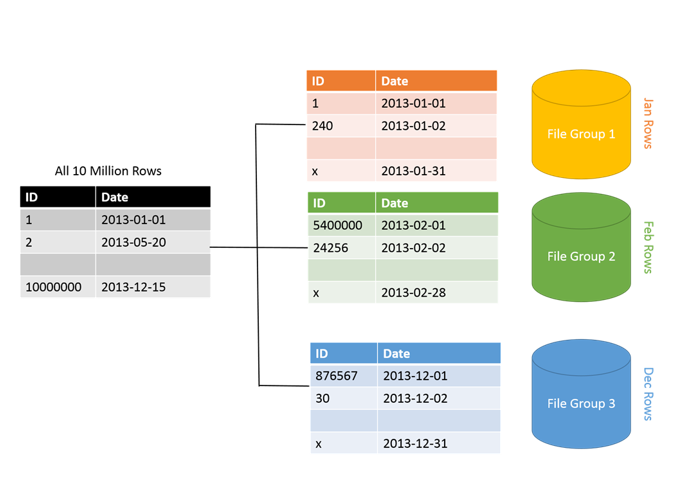
Why Table Partition is Required ?
- Reduce the performance issue like “Inserts, updates and deletes on large tables can be very slow and expensive, cause locking and blocking, and even fill up the transaction log”.
- Easy and less time consuming for database maintenance i.e. Backup & restoration for individual partitions instead of the whole table , compress data in one or more partitions or rebuild one or more partitions of an index.
- Enabling lock escalation at the partition level instead of a whole table. This can reduce lock contention on the table. To reduce lock contention by allowing lock escalation to the partition, set the LOCK_ESCALATION option of the ALTER TABLE statement to AUTO.
- In same context it’s not possible to do archiving data due to compliance or cultural requirements
- For performance , the query optimizer can process equi-join queries between two or more partitioned tables faster when the partitioning columns are the same as the columns on which the tables are joined.
- Database backup and restore strategy (support for partial database availability)
- Index maintenance strategy (rebuild), including index views
- Data management strategy (large insert or table truncates)
- End-user database workload
- Maximized processors usages can be ensured through Parallel partition processing that satisfy the query for a partition table.
- Also this parallel feature can be enabled or disabled based on the usage requirements.
- It can speed up loading and archiving of data by using partition switching : For example, an operation such as loading data from an OLTP to an OLAP system takes only seconds
- To improve data sorting performance, stripe the data files of your partitions across more than one disk by setting up a RAID. In this way, although SQL Server still sorts data by partition, it can access all the drives of each partition at the same time.
When to Use?
- In a clustered table, partition column should be part of primary key or clustered key.
- By default, indexes created on a partitioned table will also use the same partitioning scheme and partitioning column that is being used by the table
- If data in a partition is not required to be modified that partition may be marked READ ONLY
- Entire table will be locked during an index rebuild operation so you can not rebuild indexes on a single partition with the ONLINE option.
- If you ever require to change partition key then you will be required to recreate the table, reload the data and rebuild the indexes.
- Partition column and partition key both should match in terms of data type, length and precision.
- Only available in Enterprise and Developer editions
- All partitions must reside in the same database
- You can rebuild indexes based on a partition instead of rebuilding the entire index.
Component of Table Partition
Partition Function
The partition function defines how to partition data based on the partition column. The partition function does not explicitly define the partitions and which rows are placed in each partition. Instead, the partition function specifies boundary values, the points between partitions. The total number of partitions is always the total number of boundary values + 1.
Range Left and Range Right
Partition functions are created as either range left or range right to specify whether the boundary values belong to their left or right partitions:
Range left means that the actual boundary value belongs to its left partition, it is the last value in the left partition.
Range right means that the actual boundary value belongs to its right partition, it is the first value in the right partition.Left and right partitions make more sense if the table is rotated:
RIGHT means < or >=
LEFT can be translated as <= and >.
Partition Scheme
The partition scheme maps the logical partitions to physical filegroups. It is possible to map each partition to its own filegroup or all partitions to one filegroup. A filegroup contains one or more data files that can be spread on one or more disks. Filegroups can be set to read-only, and filegroups can be backed up and restored individually. There are many benefits of mapping each partition to its own filegroup. Less frequently accessed data can be placed on slower disks and more frequently accessed data can be placed on faster disks. Historical, unchanging data can be set to read-only and then be excluded from regular backups. If data needs to be restored it is possible to restore the partitions with the most critical data first.
Placing your partitions on separate filegroups is to make sure that you can independently perform backup operations on partitions. This is because you can perform backups on individual filegroups.
How can you get information about Partition
Catalog views to get information about the partitioned tables, indexes, the partition functions, and partition schemes.Here’s the list of catalog views available and a brief description of each:
- sys.partition_functions - returns information about partition functions
- sys.partition_parameters - returns information about parameters of partition functions
- sys.partition_range_values - returns information about partition function's boundary values
- sys.partition_parameters - returns information about parameters of a partition function
- sys.partition_range_values - returns information about boundary values of a partition function
- sys.partition_schemes - returns information about partition schemes
- sys.data_spaces - returns information about partition schemes
- sys.destination_data_spaces - returns information about individual partition schemes
- sys.partitions - returns information about partitions
- sys.tables - returns information about partitioning of tables
- sys.indexes - returns information about partitioning of indexes
- sys.index_columns - returns information about partitioning of indexes
For example, following query gives you partition numbers and an approximate number of rows in each partition of the Orders table:
SELECT partition_id, object_id, partition_number, rows
FROM sys.partitions
WHERE object_id = OBJECT_ID('InternetUsers')